Thus far in this series, I’ve focused on various ways to align with ecosystems and communities and create or integrate with platforms. This is designed to maximize the engineering economics of your business, reducing costs, outsourcing maintenance, and benefiting from innovation that comes from outside your employer or core engineering team. But if you’re running a business, you’re probably asking, “that’s great, but how do I make money?” In the past, my snarky answer was, “create a great product that reduces your customers’ pain and saves them time. Duh…” But as time goes on, I’ve realized that what they’re really asking is how to benefit from open source innovation without giving away your core value for free. That is to say, how do you do this open source stuff and still create a moat that prevents competitors from stealing your milkshake while you establish lucrative business relationships with your customers and partners?
Open Source Heirarchy of Products
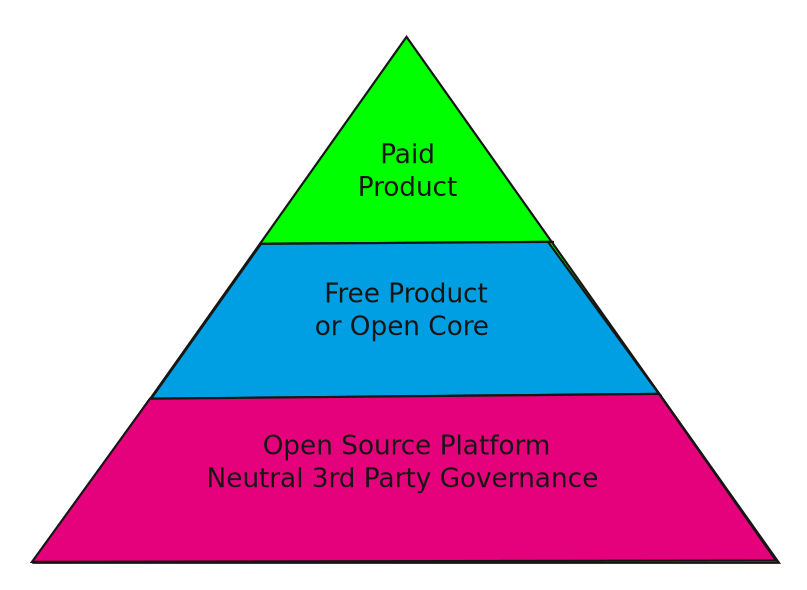
Thus far in this series, I’ve focused on the lower parts of the above pyramid. In this post, I’m going to focus on the upper parts. The lower 3rd, which focuses on platforms, is about cost, the bottom line, and generating enough innovation that provides lift to the 2 upper layers. Platforms are about engineering economics – how do I accelerate innovation for less money than I would spend if I did it all myself. It’s about delegation, ecosystem integration, neutral 3rd parties, and open governance. The 2 upper layers about about taking the platform innovation and applying it to customer use cases; going to market and showing product-market fit. The bottom layer is a shared resource. The top layers are all yours. Even then, there’s an art to constructing your products to give you the best chance to thrive. You’ll notice that I break this section into 2 layers and not one. Even when the product is 100% yours, there’s a need to diversify your customer base and think about the multiple personas you want to bring into your fold.
The “Freemium” or Open Core Layer
No product category has been as poorly understood as open core or other “free to use” products. In the early to mid 2000s, there was a simple model for getting investors to put money into a startup: take an established open source project and “commercialize” it, stripping it of just enough features so that you could convince users to convert into paying customers in order to get the “creamy frosting” of paid features. This model produced a smattering of successes, but most of the companies who tried it failed. Invariably, the paid product would compete with the free version, thus incentivizing the company leaders to put more and more features into the paid version and less into the free one. The end result was a bunch of unhappy users who abandoned the project and blunted whatever momentum the commercial product may have had. I do not recommend this approach.
These days, I think about core platforms like Kubernetes, with free products built around it, such as the many freely available but commercial Kubernetes distributions, and then the for-pay vertical applications built on that. Each layer of the product stack is designed for a different audience and fulfills a different purpose. No one is going to take plain, vanilla Kubernetes and sell you the software bits, but they might provide an easy-to-use bundled version with some limitations for personal use, and then sell you a full product with proprietary extensions and plugins. The base platfrom from the Cloud Native Computing Foundation is designed for and by core contributors; the free bundle or distribution is for end users or “developer users” who want to try it out or use it for limited applications; and the commercial bundle with for-pay plugins and extensions is for customers with specific needs and little time for implementation. All are segments with different needs and all have value in the kubernetes ecosystem, with vendors tailoring their solutions to various use cases.
In some cases, the free product skips the base platform entirely and is its own entity. One example of this is Splunk, which gave away a proprietary and limited but free product and provided a convenient means for customers to buy the full version. Splunk avoided the fate of the open core failures by ensuring that its free product always had an audience and always provided value, even for users who didn’t pay for it. The founders of Splunk debated whether to open source their product and ultimately decided they could delivery value for free customers without open sourcing – and they were proven correct. Because they never needed outside contributors to reduce costs, and because they could sustain the innovation required to land paying customers, open source wasn’t as compelling for their product strategy. Keep this in mind when I discuss agentic products below.
Having a free product can make the difference between surviving and thriving, but you must be thoughtful of your goals and mindful of the drawbacks of different approaches. There are a couple of things you should keep in mind:
- All free products should provide something of value for customers who don’t pay. There are some customers who will never ever pay for your product. Are you ok with them leaving your sphere of influence and going elsewhere? What is the value of growing your brand recognition? Can you do that without a free product?
- Your free product is your intellectual property. The platform is the place for neutral 3rd party governance. Your free product is yours to do with as you please, whether it’s released under an open source license or not. Of course, it’s best to treat your community with respect: your free product is there to create brand ambassadors who will vouch for your company.
- A free product with an open source license can be beneficial to your overall product strategy. You have to decide whether the benefits outweigh the costs. It is an expression of transparency and trust that your customers will appreciate. And you can protect yourself through copyright and trademark law. It can also accelerate your brand recognition and growth in ways that a typical proprietary free product cannot, but not always. And therein lies the rub: It depends on who your customers are and their expectations.
- If you view your free product as competition to your paid version, you’ve already failed. Either you fail to understand the value of a free product, or you’ve implemented your product strategy poorly. Either way, you would do well to take a step back and rethink your strategy. Hopefully, you see this in time to course correct.
The Paid Product
The interesting part of paid products is that there are so many potential avenues to take. Whereas platforms and free products are relatively straightforward, paid products can take on a variety of shapes, sizes, and types: *-as-a-service; software bundles; paid consultation service; vertical integration; vertical customer use case; etc. This makes it easier to separate out the core value proposition of your paid solution, but it also makes it trickier to establish a conduit from free to paid. For example, if your solution is SaaS, does it make sense for your free product to a be downloadable open source software bundle? Possibly – there is enough market differentiation such that the free product will not detract from the SaaS experience, but usually, you want the free version to be easy to use so that your technology becomes more ubiquitous. A difficult to configure software bundle would take a significant effort for you to maintain and may not add enough of a benefit to justify the expense. Then again, if a free bundle enables other businesses to embed your technology and become potential OEM partners, it could allow you to expand your business in ways you hadn’t thought of. As long as giving away your product adds value to your overall product strategy and accelerates the growth of your paid solution, then it’s justifiable.
The Agentic Wrinkle
I’ve argued in the past that agentic engineering was going to change the open source landscape significantly – there will be more open source software, not less, and a growing number of companies will need a solid open source strategy, probably more than ever before. I wrote this series for 2 main reasons:
- Large numbers of startup founders are taking a crash course as we speak in open source ecosystems and strategies. I want them to think through their approaches, consider what they want to achieve, and decide whether an open source approach will benefit them.
- In a world where autonomous software agents will write an increasing share of our source code, rules of transparency and governance in software collaboration are more important than ever. The risks are also higher than ever. This is a world where your competitors can copy your features almost as soon as you release them. How are you going to protect your business?
Agentic engineering holds great promise for entrepreneurs. I’ve seen companies with just 2 co-founders deliver a ready-to-order product without needing to hire a team of developers. This is astounding! But I’ve also seen startups get attacked by no-innovation companies that only repackage their code and still get millions in investment dollars. The emergence of agentic engineering tips the scales in a few interesting ways.
- Platforms are still valuable. In fact, having a neutral location for platform development may be more valuable than ever – a dynamic, growing platform will also attract agentic development, which means the platforms will become more dynamic and robust, providing more growth fuel for your intellectual property.
- Protect your intellectual property. Releasing a free product as open source may actually be more safe than a proprietary version with no source code. Open source code released under your trademark and copyright gives you a way to audit what competitors release. Embedding clues within your code will help you determine if other companies rebranded your intellectual property, whereas an agent reverse-engineering the features of your proprietary product will be almost undetectable.
- You will have to adapt. For every startup out there: the game has changed. Our entire way of designing, building, testing, and delivering software has changed forever and is about to rewrite its existence. Entire platforms will be torn down and replaced by new ones with incredible speed. If you haven’t adopted this methodology, you will be left behind.
There are some incredible challenges ahead. In the past, companies could separate their free from paid products through data. The software was free, but the data or “content” was what customers paid for. In an agentic world, data is a core part of any product. There is no such thing as software-only solutions in an agentic world. And in a world where agents can regenerate content with striking speed, this is no longer the product moat that it once was. Tech vendors will have to learn how to deliver free agentic tools, complete with data, that will still provide an avenue for conversion to paid, commercial solutions.
As you think through your product strategy, consider these questions:
- Platforms: What is your platform strategy? Where is collaboration within an ecosystem helpful?
- Free products: What can you give away for free that will accelerate your growth strategy?
- Paid products: How can you create a compelling product over and above what’s available for free?
- Agentic engineering: How will you benefit from an agentic world? How do you protect your value proposition?