There is a long history of products that were solutions looking for problems, but none were as exasperating, futile, and devoid of application like software composition analysis, or SCA, the dumb database of security “products”. More ambulance-chasing than providing anything useful, SCA vendors were the personal injury lawyers of the technology world. Initially, they started life as an attempt to help enterprises get a handle on the vast quantities of open source dependencies and frameworks they used to build applications, especially with respect to license compliance. That proved to be a pretty limited source of revenue, however, so SCA vendors moved on to something they could seek legitimate rent from: scaring the bejesus out of CIOs everywhere and convincing them that open source was scary stuff that needed to be held at arm’s length no matter the cost. That is to say, they morphed into a security product category and spent their time convincing customers that they were at great risk from all this open source stuff, and only the SCA vendors could help customers avoid an apocalyptic end. It didn’t help that some rather large enterprises misconfigured their systems and allowed hackers to exfiltrate sensitive data – I’m looking at you Equifax.
These data breaches would have been prevented by better security processes and more secure configurations, but it was the SCA vendors that decided to emphasize the role of open source software. It was the SCA vendors that exaggerated the exploitability of every published security vulnerability, no matter how little it applied to a given application’s context, because SCA vendors didn’t care about context. Even the log4j vulnerability, as bad as it was, was only vulnerable in specific circumstances. But good luck explaining that one to your CISO after the SCA vendors had their way. It was the SCA vendors that prevented enterprises from participating in open source communities because they convinced their customers that collaborating upstream would dirty their bottoms and give them a case of the ick. it’s because of the SCA vendors that I have had great difficulty convincing my technology leaders of the value of contributing to open source projects. So no, I will shed no tears for the death of an industry category that caused more harm than good and is at least partially responsible for the terrible state of affairs that is open source maintainership.
What is SCA?
For those who never had the misfortune of being subjected to these “products”, you may be forgiven for wondering just what all the fuss is about and why you should care. here is a very simple overview:
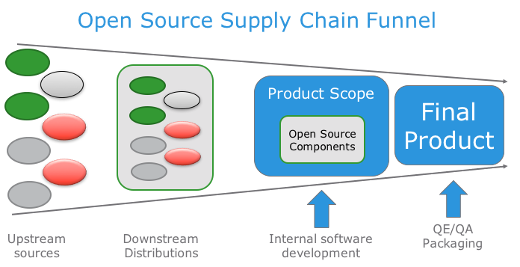
- Take a source code repository, probably in git, and look at the language it’s written in. If it’s python-based, there will be a file called “requirements.txt” and if it’s Java-based, there will be a file called “pom.xml”.
- Those files contain lists of libraries or software “dependencies” that are needed to use or run the software in your source code repository
- The SCA scanner looks at those libraries, determines if there are other dependencies that will be used but are not on the list (I’m not going to get into the details of this), and analyses their metadata. Note: the SCA scanner does not actually scan the software; it only scans the metadata that describes the software: version numbers, licensing, file size, etc
- After compiling a list of all the dependencies it can find, the SCA scanner phones home and compares your metadata to its database, looking for version matches
- In its massive metadata library, the SCA scanner looks up published security vulnerabilities and determines the likelihood that your software is using vulnerable libraries, based on the matches it finds
- The SCA vendors often supplement the publicly available vulnerability data with their own proprietary research data that they don’t share because why would they want to solve security problems? That doesn’t increase their revenue share
- The SCA scanner then provides you a list of vulnerable software and gives you a score of how risky it is based on published security analysis.
This is SCA scanning in a nutshell. Note that at no point do they actually analyze any software. They only match metadata with security data and then give you their best guess as to whether it applies to you. Given that they are incentivized to amplify whatever risk you actually face, don’t count on them being very accurate or proactively removing false positives. They would much rather terrify you into believing you have a severe problem that you need to pay millions of dollars to rectify. SCA vendors have no idea if a particular vulnerability makes your software less secure (this is changing, but these vendors have been loathe to provide this context, because it undermines their value proposition). At its heart, an SCA scanner is a predictive analysis tool that tries to tell you how much security risk you have incurred with your software. If I modify a library or its configuration to improve the security, the SCA tool isn’t smart enough to understand that and will simply label your modified software with the same metadata analysis as the unmodified version. It’s a dumb tool that abhors nuance and besides, it’s better for the SCA vendor if they can tag as many libraries as possible with the high severity security vulnerability label.
For inexplicable reasons, this industry category has been around for over 20 years now, and it is finally dying. Agentic engineering systems are rendering it null and void. This is ironic, because autonomous agents are able to find and exploit vulnerable software faster than ever, so you might think that SCA tools are needed more than ever. And yet, it’s the agentic tools that can now find and fix vulnerabilities just as quickly. In fact, agentic systems uncover and fix vulnerabilities so quickly that there’s little time to publish vulnerability data in a dumb metadata library. This is going to accelerate so quickly that the need for SCA scanning, such that it ever existed, will approach zero. Why would I need an SCA scanner when the software in question has already been updated, with a fixed version published for my consumption? Why would I need a predictive analysis tool when I can systematically retrieve the fixed versions of software as quickly as you can publish the software metadata? That’s just it: I won’t need a predictive analysis tool. Just give me the bits.
Death to SCA vendors. May they waste away slowly and painfully.