We had a very enlightening conversation with Craig McLuckie, he of Kubernetes and Heptio fame. We talked about the simplicity of the Heptio model, the crowded field of container orchestration and a bit of Kubernetes history. Click below to hear more!
For those of us who follow open source business trends and products, we were blessed with a landmark announcement today from Toyota: the 2018 Camry will feature an entertainment system based on Automotive Grade Linux (AGL), the Linux Foundation collaborative project that counts car makers Toyota, Honda, Suzuki, Mazda, Mercedes-Benz and Nissan as members.
AGL is an open source project hosted by The Linux Foundation that is changing the way automotive manufacturers build software. More than 100 members are working together to develop a common platform that can serve as the de facto industry standard. Sharing an open platform allows for code reuse and a more efficient development process as developers and suppliers can build once and have a product work for multiple OEMs. This ultimately reduces development costs, decreases time-to-market for new products and reduces fragmentation across the industry.
The Linux Foundation has led the effort to help more industries become collaborative in an effort to become more efficient at product development. The auto industry is a logical choice, because very few people buy a car based on who makes the entertainment system, so why not collaborate on the base functions and innovate on top of that platform?
I’ll be interested to learn more about Toyota’s product development and how they go about putting together the final version that you’ll see in your car. Expect more on this story soon.
Ever since the mass adoption of Agile development techniques and devops philosophies that attempt to eradication organizational silos, there’s been a welcome discussion on how to optimize development for continuous delivery on a massive scale. Some of the better known adages that have taken root as a result of this shift include “deploy in production after checking in code” (feasible due to the rigorous upfront testing required in this model), “infrastructure as code”, and a host of others that, taken out of context, would lead one down the path of chaos and mayhem. Indeed, the shift towards devops and agile methodologies and away from “waterfall” has led to a much needed evaluation of all processes around product and service delivery that were taken as a given in the very recent past.
In a cloud native world, where workloads and infrastructure are all geared towards applications that spend their entire life cycle in a cloud environemnt, One of the first shifts was towards lightning fast release cycles. No longer would dev and ops negotiate 6 month chunks of time to ensure safe deployment in production of major application upgrades. No, in a cloud native world, you deploy incremental changes in production whenever needed. And because the dev and test environments have been automated to the extreme, the pipeline for application delivery in production is much shorter and can be triggered by the development team, without needing to wait for a team of ops specialists to clear away obstacles and build out infrastructure – that’s already done.
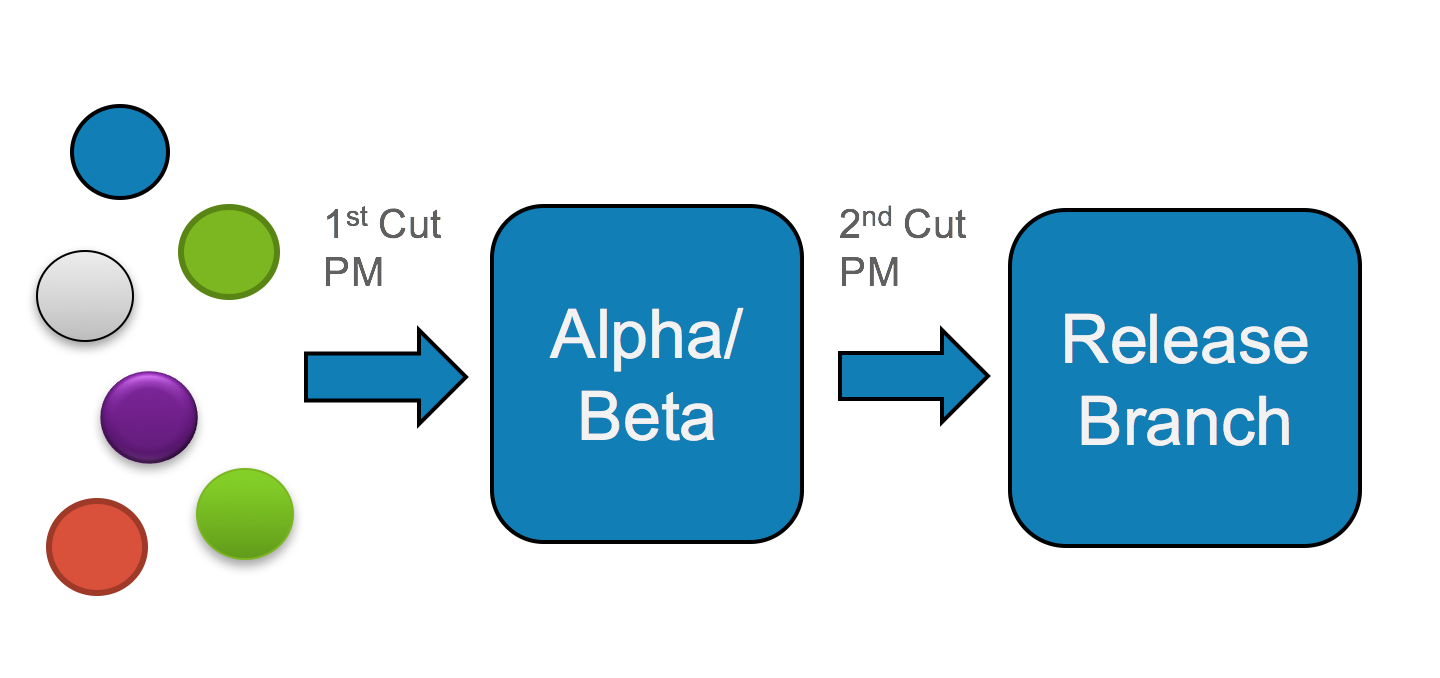
Let me be clear: this is all good stuff. The tension between dev and ops that has been the source of frustration over the centuries has left significant organizational scar tissue in the form of burdensome regulations enforced by ops teams and rigid hierarchies which serve to stifle innovation and prevent rapid changes. This is anathema, of course, to the whole point of agile and directly conflicts with the demands of modern organizations to move quickly. As a result, a typical legacy development pathway may have looked like this:
3-stage development process, from open source components to 1st software integration to release-ready product
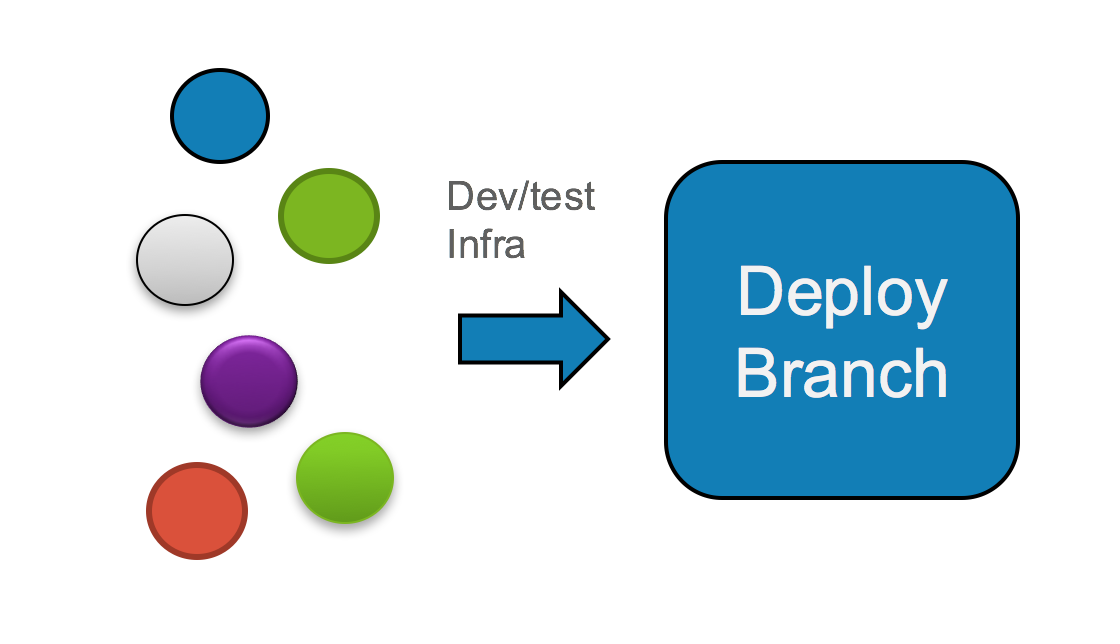
In the eyes of agile adherents, this is heretical. Why would you waste effort creating release branches solely for the purpose of branching again and going through another round of testing? This smacks of inefficiency. In a cloud native world, developers would rather cut out the middle step entirely, create a better, comprehensive testing procedure, and optimize the development pipeline for fast delivery of updated code. Or as Donnie Berkholz put it: this model implies waterfall development. What a cloud native practitioner strives for is a shortened release cycle more akin to this:
2-stage process, from open source components to deployable product
Of course, if you’ve read my series about building business on open source products and services, you’ll note that I’m a big advocate for the 3-step process identified in figure 1. So what gives? Is it hopelessly inefficient, a casualty of the past, resigned to the ash heap of history? I’ll introduce a term here to describe why I firmly believe in the middle step: orthogonal innovation.
Orthogonal Innovation
In a perfect world, innovation could be perfectly described before it happens, and the process for creating it would take place within well-defined constructs. The problem is that innovation happens all the time, due to the psychological concept of mental incubation, where ideas fester inside the brain for some indeterminate period of time, until finding its way into a conscious state, producing an “Aha!” moment. Innovation is very much conjoined with happenstance and timing. People spawn innovative ideas all the time, but the vast majority of them never take hold.
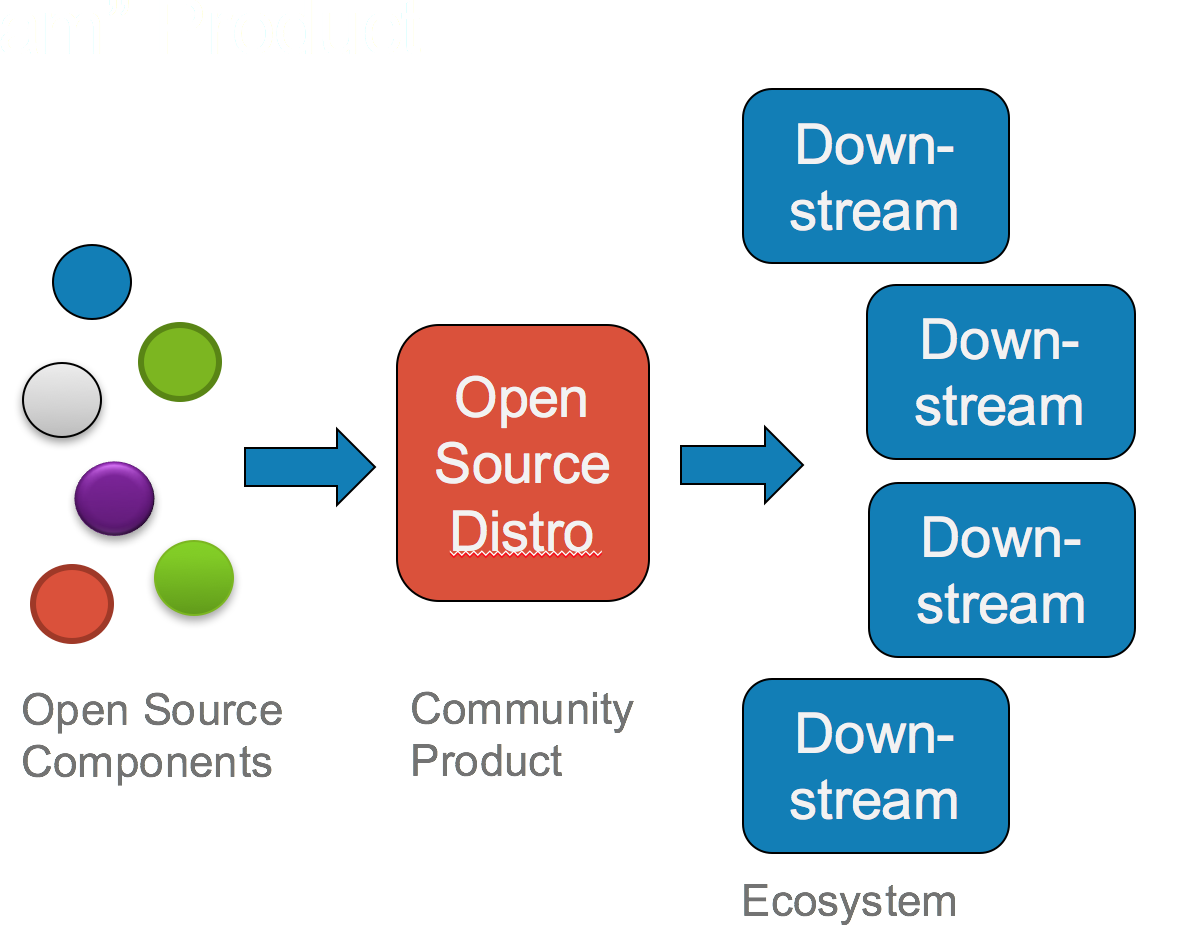
As I wrote in It Was Never About Innovation, the purpose of communities created around software freedom and open source was never to create the most innovative ecosystems in human history – that was just an accidental byproduct. By creating rules that mandated all parties in an ecosystem were relative equals, the stage was set for massively scalable innovation. If one were to look at product lifecycles solely from the point of view of engineering efficiency, then yes, the middle piece of the 3-stage pathway looks extraneous. However, the assumption made is that a core development team is responsible for all necessary innovation, and none more is required. That model also assumes that a given code base has a single purpose and a single customer set. I would argue that the purpose of the middle stage is to expose software to new use cases and people that would have a different perspective from the primary users or developers of a single product. Furthermore, once you expose this middle step to more people, they need a way to iterate on further developments for that code base – developments that may run contrary to the goals of the core development team and its customers. Let’s revisit the 3-stage process:
In this diagram, each stage is important for different reasons. The components on the left represent raw open source supply chain components that form the basis for the middle stage. The middle stage serves multiple entities in the ecosystem that springs up around the code base and is a “safe space” where lots of new things are tried, without introducing risk into the various downstream products. You can see echoes of t his in many popular open source-based products and services. Consider the Pivotal Cloud Foundry process, as explained by James Watters in this podcast with Andreessen Horowitz: raw open source components -> CloudFoundry.org -> Pivotal Cloud Foundry, with multiple derivatives from CloudFoundry.org, including IBM’s.
As I’ve mentioned elsewhere, this also describes the RHEL process: raw components -> Fedora -> RHEL. And it’s the basis on which Docker is spinning up the Moby community. Once you’ve defined that middle space, there are many other fun things you can do, including building an identity for that middle distribution, which is what many open source communities have formed around. This process works just as well from an InnerSource perspective. Except in that case, the downstream products’ customers are internal, and there are multiple groups within your organization deriving products and services from the core code base in the middle stage. Opening up the middle stage to inspection and modification increases the surface area for innovation and gives breathing room for the more crazy ideas to take shape, possibly leading to their becoming slightly less crazy and useful for the other downstream participants.
Addendum: none of the above necessitates a specific development methodology. It could be agile, waterfall, pair programming or any other methodology du jour – it’s immaterial. What matters is constructing a process that allows for multiple points of innovation and iterative construction, even – or especially – where it doesn’t serve the aims of a specific downstream product. You want a fresh perspective, and to get that, you have to allow those with different goals to participate in the process.
Product Management in Open Source can be an overlooked topic. Asking questions to define what open source really is, its overall value to a product and what options there are when attempting to scale a project can enable a product to grow with minimal pains. This presentation is an overview on the topic and its details.
We had a great talk with Jono Bacon, community leader extraordinaire. Jono spent many years as the Ubuntu community leader, founded the Community Leadership Summit (CLS – now taking place in Austin, TX, as we speak), wrote the book The Art of Community, and has now started his own consulting practice, Jono Bacon Consulting.
We talked about all things community-related, including the intersection between community development, devops, and product management. It was a great discussion, and I hope you enjoy listening as much as we enjoyed talking.
Rikki Endsley is the guru who runs the community for OpenSource.com – and does a whale of a job. Stephen is an open source engineering consultant at Docker and blogs for OSEN and at Medium
I love talking about supply chain management in an open source software context, especially as it applies to managing collaborative processes between upstream projects and their downstream products. In the article linked above, I called out a couple of examples of supply chain management: an enterprise OpenStack distribution and a container management product utilizing Kubernetes and Docker for upstream platforms.
What about anti-patterns or things to avoid? There are several we could call out. At the risk of picking on someone I like, I’ll choose Canonical simply because they’ve been in the headlines recently for changes they’ve made to their organization, cutting back on some efforts and laying off some people. As I look at Canonical from a product offering perspective, there’s a lot they got right, which others could benefit from. But they also made many mistakes, some of which could have been avoided. First, the good.
What Canonical Got Right About Supply Chains
When the Ubuntu distribution first started in 2004, it made an immediate impact; the kind of impact that would frankly be impossible today for a Linux distribution. Remember what was happening at the time: many, many Red Hat Linux distribution users were feeling left out in the cold by Red Hat’s then groundbreaking decision to fork their efforts into a community stream and a product stream. One of the prevailing opinions at the time was that Fedora would be treated like the red-headed stepchild and starved for resources. Unfortunately, Red Hat played into that fear by… initially treating Fedora like the red-headed stepchild and almost willfully sabotaging their own community efforts. (for a good run-down of the 2004 zeitgeist and some LOL-level hilarity, see this page on LWN).
Ubuntu never had that problem. From the very outset, there was never any doubt that Mark Shuttleworth and crew meant what they said when they set out to deliver an easy-to-use, free distribution. Lots of people tried to do that, but Ubuntu went about it more intelligently and made a lot more progress than its predecessors. Where did they succeed where others failed?
They chose a great upstream platform. Instead of building something from scratch (which would have taken forever) or using the abandoned Red Hat Linux or even Mandrake, which were both going through awkward transitional phases (one to Fedora and the other out of the Red Hat orbit), they built Ubuntu on a rock-solid, dependable, community-maintained Linux distribution: Debian. openSUSE was not yet a thing, and building on SuSE Linux would have tied Ubuntu to the fortunes of SuSE and Novell, which would have been a bad idea. Slackware was long in the tooth, even then. Debian had its own challenges, not the least of which was a clash of cultures between free culture diehards and a group of people starting a for-profit entity around Debian, but it worked for Ubuntu’s purposes. It was also a challenge to install, which provided a great opportunity for an upstart like Ubuntu.
Their supply chain was highly efficient, which is directly related to the above. Contrast this to what I’ll say below, but in the case of the base platform they started from, the software supply chain that made up Ubuntu was reliable and something its developers and users could depend on.
They invested in the user experience and community. Ubuntu classified itself, at least back then, as “Linux for humans”, which spoke to the fact that, up until then, using Linux was an esoteric and mistake-prone set of tasks. It was the sort of thing you did in your spare time if you were a CS or EE major looking to construct a new toy. Ubuntu changed all that. They made Linux much easier than any previous desktop Linux initiative. From a supply chain perspective, they did this great UX work as participants in the greater Gnome community. I realize some Gnome folks may blanch at that statement, but by and large, Ubuntu was very much depicted as Gnome people, and they were making contributions to the greater effort.
They scaled globally, from the beginning. It was awe-inspiring to see all the local communities (LoCos, in Ubuntu parlance) spring up around the world dedicated to evangelizing Ubuntu and supporting its users. This happened organically, with Canonical providing support in the form of tooling, broad messaging, and in some cases, on the ground resources. Ubuntu also employed a formidable community team helmed by Jono Bacon, who accelerated Ubuntu’s growth (I once chided Jono on a community managers panel at OSCON about how easy he had it as the Ubuntu community lead. I still chuckle over that). One cannot emphasize enough that when this massive global community kicks into gear, the effect on upstream supply chains is tremendous. A hefty number of these global users and developers also became participants in many of the upstream communities that fed into Ubuntu. It’s one of the great examples of increased participation yielding positive results for everyone in the ecosystem, including Canonical.
They were early adopters of “cloud native” workloads. As Simon Wardley will never let us forget, Canonical bought into cloud-based workloads before any other Linux vendor. It was their work in 2008-2009 that really cemented Ubuntu’s status as *the* primary and default platform for all new cloud and server-based technologies, which continues to this day. Even now, if a new project wants to get early adoption, they release .DEBs on Ubuntu and make sure it builds properly for those Ubuntu users and developers who download the source code. It gives Ubuntu and Canonical an incredible advantage. Again, from a supply chain perspective, this was gold. It meant that the upstream supply chain for cloud native tools was heavily Ubuntu-centric, wrapping it all together with a nice bow.
Where it Went Pear-shaped
In writing about everything they got right, I am of course using the rhetorical device of setting up the reader for a barrage of things they got wrong. This is that section. For all of their incredible acumen at scaling out a global community around a Linux distribution, they failed to learn from their supply chain success, and instead started down the path of NIH syndrome. You’ll see lots of critiques elsewhere pertaining to other challenges at Canonical, but I’ll focus on their supply chain strategy, and how it failed them.
Launchpad. The first sign that Canonical were moving away from their established supply chain methodology was when they first released Launchpad, a web-based service for developers to create, share, and collaborate on software projects. It also featured an auto-build service and an easy way to release and manage unofficial builds of bleeding edge software: the “Personal Package Archive” or PPA. The service was great for its time and highly ambitious. And when Canonical announced they were open-sourcing it, even better. But there were problems: maintaining a code base for a service as complex as Launchpad is really difficult. Even with an entire company devoted to such a concept, there are still major challenges. There were a couple of ways to deal with that complexity: upstream as much as possible to defray the cost of maintaining the code and/or create a long-term revenue model around launchpad to sustain its development. Canonical did neither. In fact, it was the worst of both worlds: they neither upstreamed the project nor created a revenue model to sustain development. In other words, Launchpad became a proverbial albatross around the neck, both in terms of technical debt to be maintained solely by the Launchpad team and in the lack of funding for future development. It was the first sign that Canonical was on the wrong track from a business strategy viewpoint. The polished user experience that Ubuntu users came to expect from their software was missing from Launchpad, giving GitHub the opportunity to build something larger.
Juju. It might be premature to write off Juju entirely, but it hasn’t become the force Canonical and Ubuntu intended it to be. Written at a time when Puppet and Chef were the young upstarts, and Ansible was but a gleam in Cobbler’s eye, Juju was Canonical’s answer to the problem of configuration management in the age of cloud. It might have had a better chance if Canonical had decided to be a bit looser with its user base. Puppet and Chef, for example, were always available on a variety of platforms, whereas Juju was specifically tied to Ubuntu. And while Ubuntu became the de facto standard for building cloud tools, the enterprise was still dominated by Windows, Unix, and RHEL. Developers may have built many tools using Ubuntu, but they deployed in production on other platforms, where Juju was not to be found. If you were an enterprising young devops professional, going with a Juju-only approach meant cutting off your air supply. Because it was Ubuntu-only, and because it was never a core part of the Debian upstream community, the impact made by Juju was limited. Canonical was unable to build a collaborative model with other developer communities, which would have improved the supply chain efficiency, and they weren’t able to use it to add value to a revenue-generating product, because their capacity for generating server revenue was limited. It’s another case of great software hobbled by a poor business strategy.
Unity. If Launchpad and Juju gave observers an inkling that Canonical was going off the rails, the launch of Unity confirmed it. From the beginning, Canonical was always a participant in the Gnome desktop community. This made sense, because Ubuntu had always featured a desktop environment based on Gnome. At some point, Canonical decided they could go faster and farther if they ditched this whole Gnome community thing and went their own way. As with Launchpad and Juju, this makes sense if you’re able to generate enough revenue to sustain development over time with a valid business model. I personally liked Unity, but the decision to go with it over stock Gnome 3 drove an even larger wedge between Ubuntu and the rest of the Linux desktop ecosystem. Once again, Ubuntu packagers and developers were caught in a bubble without the support of an upstream community to stabilize the supply chain. This meant that, once again, Canonical developers were the sole developers and maintainers of the software, further straining an already stretched resource.
Mir. I don’t actually know the origins of Mir. Frankly, it doesn’t matter. What you need to know is this: the open source technology world participated in the Wayland project, whose goal was to build a modern successor to the venerable X.org windows server, and Canonical decided to build Mir, instead. The end. Now, Mir and Unity are, for all intents and purposes, mothballed, and Wayland is the clear winner on the desktop front. Supply chains: learn them, live them, love them – or else.
Ubuntu mobile / Ubuntu phone. The mobile space is extremely difficult because the base hardware platforms are always proprietary, as mandated by the large carriers who set the rules for the entire ecosystem. It’s even more difficult to navigate when you’re launching a product that’s not in your area of expertise, and you try to go to market without a strong ecosystem of partners. The iPhone had AT&T in its corner. The Ubuntu phone had… I’m not even sure. Ubuntu phone and the mobile OS that ran on it were DOA, and they should have understood that much sooner than they did.
Ubuntu platform itself. I know, I spent the first half of this article talking up the great success of Ubuntu, but there is one place where it never excelled: it never became a large enough revenue generator to sustain the many other projects under development. There was also never a coherent strategy, product-wise, around what Ubuntu should grow up to become. Was it a cloud platform? Mobile platform? Enterprise server? Developer workstation? And there was never an over-arching strategy with respect to the complementary projects built on top of Ubuntu. There was never a collective set of tools designed to create the world’s greatest cloud platform. Or enterprise server. Or any of the other choices. Canonical tried to make Ubuntu the pathway to any number of destinations, but without the product discipline to “just say no” at the appropriate time.
I get no joy from listing the failings of Canonical. I remain a great fan of what they accomplished on the community front, which as far as I can tell, is without parallel. Not many companies can claim with any credibility that they fostered a massive, global community of users and developers that numbered in the millions and covered every country and continent on the planet, driven by organic growth and pursued with a religious zeal. That is no small feat and should be celebrated. My hope is that this is what Ubuntu, Canonical, and yes, Mark Shuttleworth, are known for, and not for any business shortcomings.
I’m not suggesting that a company cannot be successful without building out an upstream supply chain – there are far too many counter-examples to claim that. What I am suggesting is that if you have limited resources, and you choose to build out so many products, you’re going to need the leverage that comes from massive global participation. If Canonical had chosen to focus on one of the above initiatives, you could argue that supply chain would not have been as important. I will note, for the record, that none of the challenges listed above are related to the fact that they were open source. Rather, to sustain their development, they needed much broader adoption. In order to sustain that model, they would have had to create a successful product with a high growth in revenue, which never came. The lesson: if you want more control over your software products, you need an accompanying product strategy that supports it. If I were at Canonical, I would have pushed for a much more aggressive upstream strategy to get more benefits from broader open source participation.
Congratulations, Docker. You’ve taken the advice of many and gone down the path of Fedora / RHEL. Welcome to the world of upstream/downstream product management, with community participation a core component of supply chain management. You’ve also unleashed a clever governance hack that cements your container technology as the property of Docker, rather than let other vendors define it as an upstream technology for everyone. Much like Red Hat used Fedora to stake its claim as owner of an upstream community. I’ll bet the response to this was super positive, and everyone understood your intent perfectly! Oh…
Just a reminder, pretty much everyone dies at the end of Moby Dick. #docker
So yes, the comparison to Fedora/RHEL is spot on, but you should also remember something from that experiment: at first, everyone *hated* it. The general take from the extended Linux community at the time was that Red Hat was abandoning community Linux in an effort to become “the Microsoft of Linux”. Remember, this level of dissatisfaction is why CentOS exists today. And the Fedora community rollout didn’t exactly win any awards for precise execution. At first, there was “Fedora Core”, and it was quite limited and not a smashing success. This was one of the reasons that Ubuntu became as successful as it did, because they were able to capitalize on the suboptimal Fedora introduction. Over time, however, Red Hat continued to invest in Fedora as a strategic community brand, and it became a valuable staging ground for leading edge technologies from the upstream open source world, much like Moby could be a staging area for Docker.
But here’s the thing, Docker: you need to learn from previous mistakes and get this right. By waiting so long to make this move, you’ve increased the level of risk you’re taking on, which could have been avoided. If you get it wrong, you’re going to see a lot of community pressure to fork Moby or Docker and create another community distribution outside of your sphere of influence. The Fedora effort frittered away a lot of good will from the Linux community by not creating an easy to use, out of the box distribution at first. And the energy from that disenchantment went to Ubuntu, leaving Fedora in a position to play catchup. That Red Hat was able to recover and build a substantial base of RHEL customers is a testament to their ability to execute on product management. However, Ubuntu was able to become the de facto developer platform for the cloud by capitalizing on Fedora’s missteps, putting them on the inside track for new cloud, IoT, and container technologies over the years. My point is this: missteps in either strategy and execution have a large and lasting impact.
So listen up, Docker. You need to dedicate tremendous resources right now to the Moby effort to make sure that it’s easy to use, navigate, and most importantly, ensure that your community understands its purpose. Secondly, and almost as importantly, you need to clearly communicate your intent around Docker CE and EE. There is no room for confusion around the difference between Moby and Docker *E. Don’t be surprised if you see a CentOS equivalent to Docker CE and/or EE soon, even though you’re probably trying to prevent that with a freely available commercial offering. Don’t worry, it will only prove your model, not undermine it, because no one can do Docker better than Docker. Take that last bit to heart, because far too many companies have failed because they feared the success of their free stuff. In this case, that would be a colossal unforced error.
This post first appeared on Medium. It is reprinted here with permission.
OH: “Every evangelist of yesteryear is now a Community Manager … at least on their biz card.”
This statement best captures a question that comes up regularly in the open source community world when you have corporations involved. Does your community manager report to engineering or marketing? It captures a number of assumptions quite nicely.
First, the concept of a “community manager” does imply a certain amount of corporate structure regardless of whether it’s for profit or some form of non-profit. If the open source licensed project is in the wild then it probably doesn’t have the size and adoption to require people with such titles. Such well-run project communities are self-organizing. As they grow and there are more things to do than vet code and commit, they accommodate new roles. They may even form council-like sub-organizations (e.g. documentation). But for the most part, the work is in-the-small, and it’s organic. The structure of well run “pre-corporate” projects is in process discipline around such work as contributions, issue tracking, and build management.
When projects grow and evolve to the point that companies want to get involved, using the project software in their products and services, then the project “property” needs to be protected differently. The software project already has a copyright (because it’s the law) and is covered by an open source license (because that social contract enables the collaboration), but trademarks and provenance can quickly become important. Companies have different risk profiles. A solution to such corporate concerns can be to wrap a non-profit structure around the project. This can mean the project chooses to join an existing foundation like the Apache Software Foundation or the Eclipse Foundation, or it could form its own foundation (e.g. the Gnome Foundation). In return for the perceived added overhead to the original community, it enables company employees to more actively contribute. (The code base for Apache httpd project doubled in the first few months after the ASF formed.)
A community manager implies more administrative structure and discipline around people coordination for growth, than the necessary software construction discipline that the early project required for growth. But a foundation often brings the sort of administrative structure for events and communications such that folks in the project (or projects) still don’t have a title of “community manager.”
Community managers are a corporate thing. And I believe they start showing up when either a project becomes a company (e.g. Apache Mesos into Mesosphere), a company wants to create a project or turn a product into a project (e.g. Hewlett Packard Enterprise with OpenSwitch), or a company wants to create a distribution of a project (e.g. Canonical with Ubuntu, Red Hat with Fedora, Cloudera with Apache Hadoop). And this is implied in the original statement about “biz cards” and questions of marketing versus engineering.
Software companies have long understood developer networks. MSDN, the Oracle Developer Network, and the IBM Developer Network have been around for decades. They are broadcast communities carrying marketing messages to the faithful. They were run by Developer Evangelists and Developer Advocates. MVP programs were created to identify and support non-employees acting in an evangelism role. These networks are product marketing programs. They tightly control access to product engineers, who allowed to appear at conferences and encouraged to write blog posts. These networks are the antithesis of the conversation that is a high functioning open source community.
I believe companies with long histories building developer networks (or employees that have such experience at new companies) make the mistake of thinking open source “community managers” belong in product marketing. They are probably using the wrong metrics to measure and understand (and hopefully support) their communities. They are falling into the classic trap of confusing community with customer, and project with product.
Liberally-licensed, collaboratively-developed software projects, (i.e. open source) is an engineering economic imperative. Because of that reality, I believe the community management/enablement role belongs in engineering. If a company is enlightened enough to have a product management team that is engineering focused (not marketing focused), then the community manager fits into that team as well.
This is a working theory for me, consistent with the successes and failures I’ve observed over the past 25 year. I would love folks feedback, sharing their experiences or expanding upon my observations.
On Tuesday, Solomon Hykes, Docker’s CTO and co-founder, unleashed the Moby Project on the world. I’ll admit I didn’t fully grasp its significance at first. This might have something to do with being on vacation in Cape Cod and not being at DockerCon, but I digress. It wasn’t until I read this Twitter thread from Kelsey Hightower that something clicked:
Project Moby will allow Docker, the product, to innovate at a pace that’s right for customers, and avoid harming the broader community.
And then it dawned on me – Docker was taking a page out of the Red Hat playbook and fully embracing the upstream supply chain model. In 2003, Red Hat decided it needed to focus on enterprise subscriptions and moved away from its free commercial linux, the venerable Red Hat Linux. In its place, Red Hat created Red Hat Enterprise Linux (RHEL), and then a funny thing happened: its employees rebelled and created the Fedora community and project, designed to be a community Linux distribution. This turned out to be a brilliant move. Forward looking technology and innovation happened in the Fedora community, and then it went through a series of hardening, polish, integration with other Red Hat platforms and bug fixes before being released under the RHEL brand. The more complex Red Hat’s product offerings became, the more valuable this model proved.
Red Hat product supply chain:
The container ecosystem shares much with the Linux ecosystem, because that’s where it came from. One of the criticisms of Docker, much like Red Hat, is that they’re “trying to control the entire ecosystem”. I may have uttered that phrase from time to time, under my breath. The Moby Project, in my opinion only, is a direct response to that. As Solomon mentioned in his blog announcement:
In order to be able to build and ship these specialized editions is a relatively short time, with small teams, in a scalable way, without having to reinvent the wheel; it was clear we needed a new approach.
Yes, any successful ecosystem becomes extremely difficult to manage over time, which is why you end up giving up control, without giving up your value proposition. This is also probably why you’ve seen Docker become more engaged on the CNCF front and why they drove the OCI formation. As David Nalley likes to say, this is the “hang on loosely, but don’t let go” approach to community-building:
There’s also the branding and trademark benefit. Just as with Fedora and RHEL, separating the branding streams now means that community-minded people know where to go: Project Moby. And prospective customers and partners also know where to go: Docker.com. It’s a great way to let your audiences self-select.
Docker decided to take the next step and embrace the open source supply chain model. This is a good thing.