From EnterpriseTech: I came across a link today to a news commentary which asserts that open source software is “a supply chain rife with security vulnerabilities and clogged with outdated versions of widely used software components.” I’m often reluctant to give these types of stories too much air time, because they’re often rife with FUD, but there’s a lot of truth here, and it’s something that we need to face up to, especially if we want companies to continue to innovate on open source platforms and build open source products.
If you read Nadia Eghbal‘s “Roads and Bridges” white paper for the Ford Foundation, you’ll see that crusty, old open source software has been a concern for some time. She proposes that we view software the same as any other core infrastructure, such as roads and bridges. There’s also a collaborate project from the Linux Foundation, the Core Infrastructure Initiative, to attempt to deal with these issues.
This is not an easy problem to solve, and it hits at the hears of what we want to do at the Open Source Entrepreneur Network, because we want companies to build process around their consumption and contribution of this great open source software and make contingency plans for when it all goes haywire. We want companies to be able to reduce their risk exposure while still benefiting from the innovation happening right now on open source platforms.
It’s a plea to look externally and figure out how your technology relates to all that’s happening in the greater ecosystem. There are still way too many companies who suffer from NIH and end up saddled with way too much technical debt. Don’t do that. Take the time and effort to make inroads into all those communities that are making all the new innovations.
This month’s topic will be all about Open Source product development in the context of mobile, edge computing, and IoT. We’ll talk about how to deal with patents and compliance, as well as a sober look at the state of security in this space and how to manage risk. And finally, we’ll touch on engineering principles in the cloud native space that allow you to benefit from upstream innovation while still delivering product reliably.
Agenda
6 – 6:30 – Meet and greet (and eat and drink)
6:30 – 7 – Patents and Mobile Computing – Deb Nicholson, Open Invention Network.
7 – 7:30 – State of Security in IoT and Edge Computing – TBD
7:30 – 8 – Product Development in Cloud Native, a Defense of the Community Distribution
We’re pleased to announce that Swapnil Bhartiya has been added to the fold of OSEN authors. Swapnil has a distinguished history writing about open source in major publications. We’re honored to have him on board. He brings a wealth of knowledge about open source in the enterprise, IoT, and consumer electronics. Look for his first contributions to appear later this month.
Want to write for us? Hit the “contact” link and tell us what you’d like to write about.
We had a very enlightening conversation with Craig McLuckie, he of Kubernetes and Heptio fame. We talked about the simplicity of the Heptio model, the crowded field of container orchestration and a bit of Kubernetes history. Click below to hear more!
For those of us who follow open source business trends and products, we were blessed with a landmark announcement today from Toyota: the 2018 Camry will feature an entertainment system based on Automotive Grade Linux (AGL), the Linux Foundation collaborative project that counts car makers Toyota, Honda, Suzuki, Mazda, Mercedes-Benz and Nissan as members.
AGL is an open source project hosted by The Linux Foundation that is changing the way automotive manufacturers build software. More than 100 members are working together to develop a common platform that can serve as the de facto industry standard. Sharing an open platform allows for code reuse and a more efficient development process as developers and suppliers can build once and have a product work for multiple OEMs. This ultimately reduces development costs, decreases time-to-market for new products and reduces fragmentation across the industry.
The Linux Foundation has led the effort to help more industries become collaborative in an effort to become more efficient at product development. The auto industry is a logical choice, because very few people buy a car based on who makes the entertainment system, so why not collaborate on the base functions and innovate on top of that platform?
I’ll be interested to learn more about Toyota’s product development and how they go about putting together the final version that you’ll see in your car. Expect more on this story soon.
Found an interesting article at “The C Suite” on the topic “CEO’s ignorance of open source software use places their business at risk“. While some of the article is a bit “FUDdy” – the author works for a company that sells risk management and mitigation, so there’s a greatest hits of open source vulnerabilities – there were also some eye-opening bits of data. To wit:
As much as 50 percent of the code found in most commercial software packages is open source. Most software engineers use open source components to expedite their work – but they do not track what they use, understand their legal obligations for using that code, or the software vulnerability risk it may contain.
We all know that developers use whatever’s available and don’t ask permission. That is not a surprise. What stood out to me was that the amount of open source code in commercial software was anywhere near 50%. Holy moly. That’s a lot of things to keep track of. When I first started this site, I had an inkling that pretty much all products consume some open source code, and I thought there should be some discussion around best practices for doing so, but I had no idea it was that pervasive. Even I, open source product person, am surprised sometimes by the near ubiquity of open source software in commercial products.
I think we’re moving beyond simply using open source software. I think we’ll see a marked shift towards optimization of usage and figuring out models to justify participation and collaboration. At least, that’s my hope. Look for more thoughts on this very subject coming up on this site soon.
Ever since the mass adoption of Agile development techniques and devops philosophies that attempt to eradication organizational silos, there’s been a welcome discussion on how to optimize development for continuous delivery on a massive scale. Some of the better known adages that have taken root as a result of this shift include “deploy in production after checking in code” (feasible due to the rigorous upfront testing required in this model), “infrastructure as code”, and a host of others that, taken out of context, would lead one down the path of chaos and mayhem. Indeed, the shift towards devops and agile methodologies and away from “waterfall” has led to a much needed evaluation of all processes around product and service delivery that were taken as a given in the very recent past.
In a cloud native world, where workloads and infrastructure are all geared towards applications that spend their entire life cycle in a cloud environemnt, One of the first shifts was towards lightning fast release cycles. No longer would dev and ops negotiate 6 month chunks of time to ensure safe deployment in production of major application upgrades. No, in a cloud native world, you deploy incremental changes in production whenever needed. And because the dev and test environments have been automated to the extreme, the pipeline for application delivery in production is much shorter and can be triggered by the development team, without needing to wait for a team of ops specialists to clear away obstacles and build out infrastructure – that’s already done.
Let me be clear: this is all good stuff. The tension between dev and ops that has been the source of frustration over the centuries has left significant organizational scar tissue in the form of burdensome regulations enforced by ops teams and rigid hierarchies which serve to stifle innovation and prevent rapid changes. This is anathema, of course, to the whole point of agile and directly conflicts with the demands of modern organizations to move quickly. As a result, a typical legacy development pathway may have looked like this:
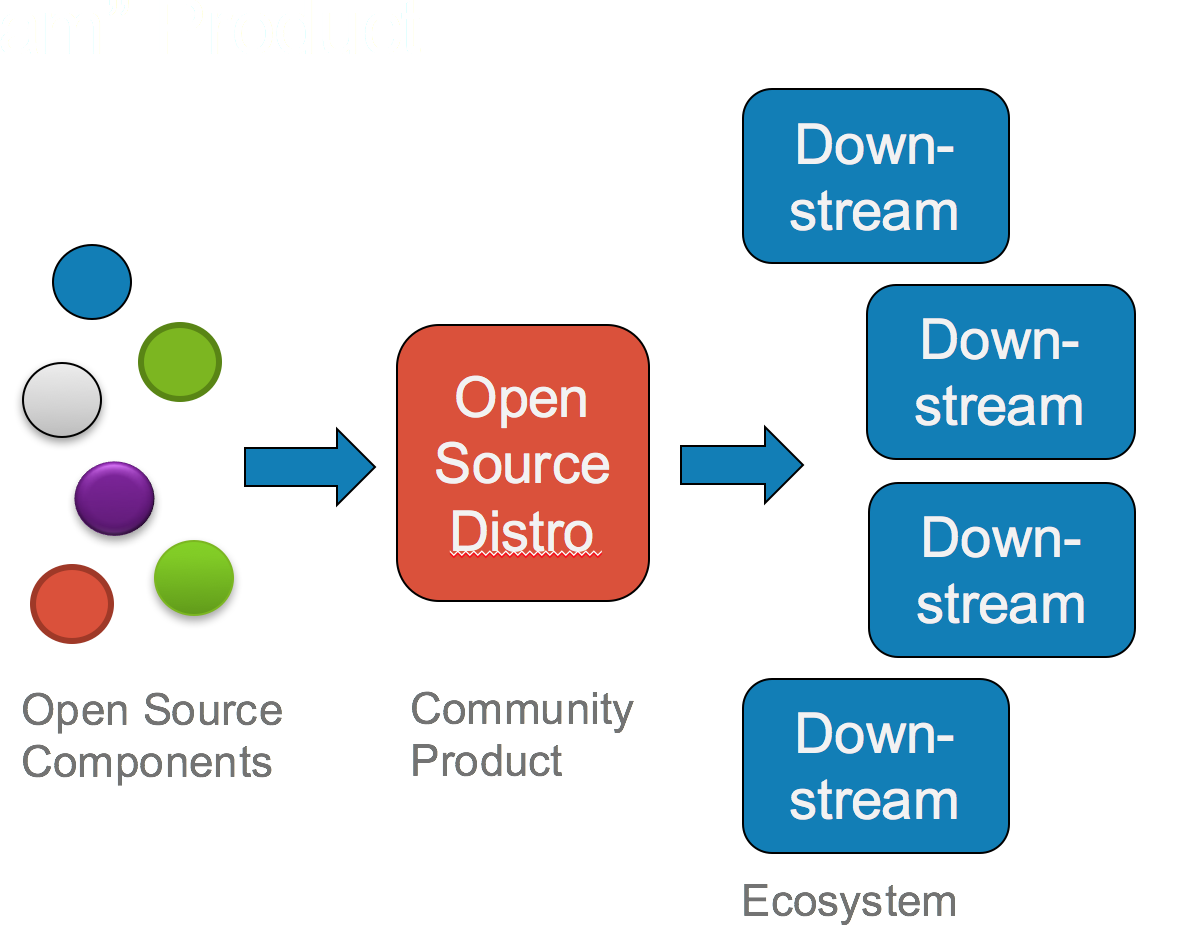
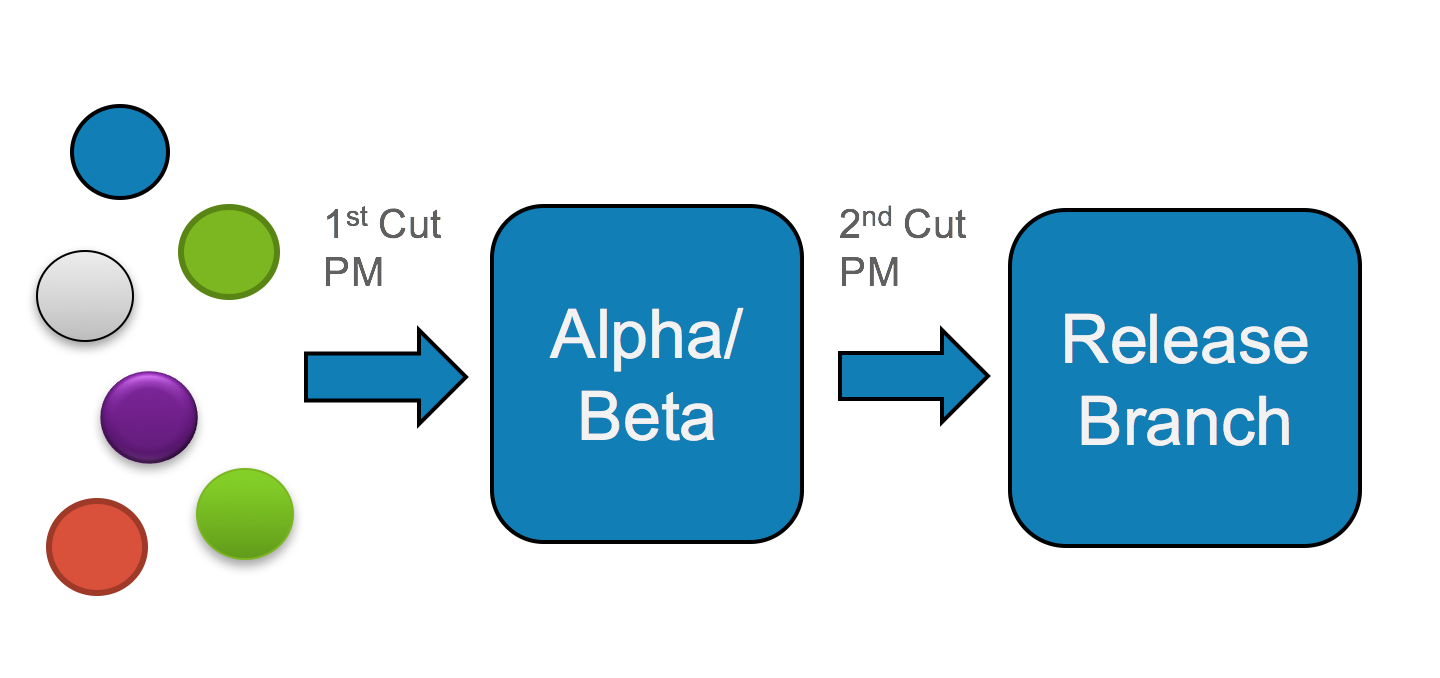
3-stage development process, from open source components to 1st software integration to release-ready product
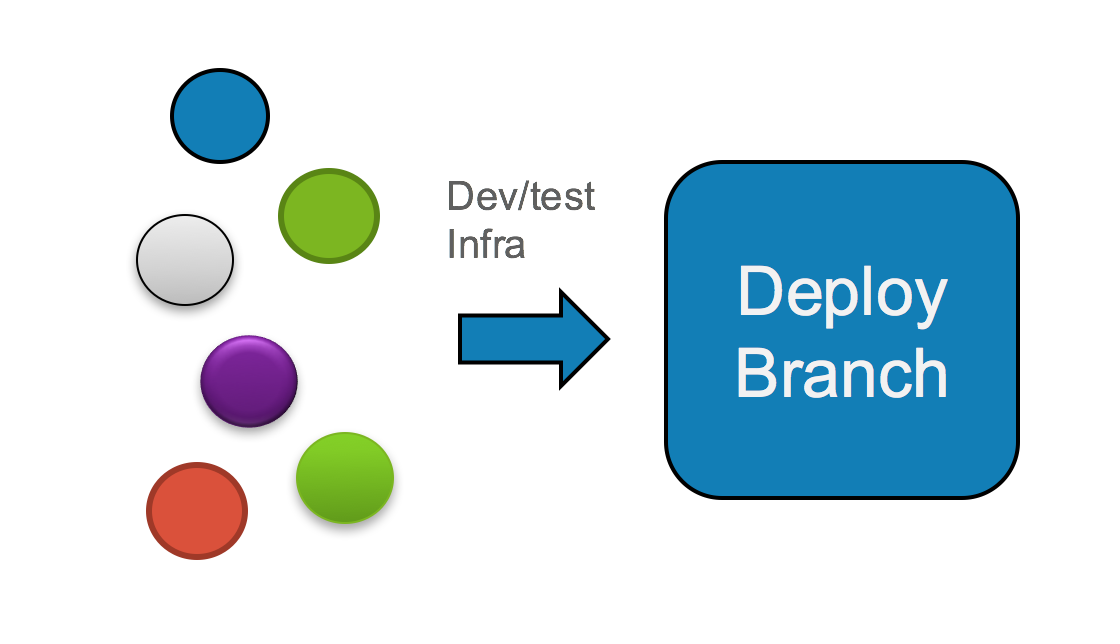
In the eyes of agile adherents, this is heretical. Why would you waste effort creating release branches solely for the purpose of branching again and going through another round of testing? This smacks of inefficiency. In a cloud native world, developers would rather cut out the middle step entirely, create a better, comprehensive testing procedure, and optimize the development pipeline for fast delivery of updated code. Or as Donnie Berkholz put it: this model implies waterfall development. What a cloud native practitioner strives for is a shortened release cycle more akin to this:
2-stage process, from open source components to deployable product
Of course, if you’ve read my series about building business on open source products and services, you’ll note that I’m a big advocate for the 3-step process identified in figure 1. So what gives? Is it hopelessly inefficient, a casualty of the past, resigned to the ash heap of history? I’ll introduce a term here to describe why I firmly believe in the middle step: orthogonal innovation.
Orthogonal Innovation
In a perfect world, innovation could be perfectly described before it happens, and the process for creating it would take place within well-defined constructs. The problem is that innovation happens all the time, due to the psychological concept of mental incubation, where ideas fester inside the brain for some indeterminate period of time, until finding its way into a conscious state, producing an “Aha!” moment. Innovation is very much conjoined with happenstance and timing. People spawn innovative ideas all the time, but the vast majority of them never take hold.
As I wrote in It Was Never About Innovation, the purpose of communities created around software freedom and open source was never to create the most innovative ecosystems in human history – that was just an accidental byproduct. By creating rules that mandated all parties in an ecosystem were relative equals, the stage was set for massively scalable innovation. If one were to look at product lifecycles solely from the point of view of engineering efficiency, then yes, the middle piece of the 3-stage pathway looks extraneous. However, the assumption made is that a core development team is responsible for all necessary innovation, and none more is required. That model also assumes that a given code base has a single purpose and a single customer set. I would argue that the purpose of the middle stage is to expose software to new use cases and people that would have a different perspective from the primary users or developers of a single product. Furthermore, once you expose this middle step to more people, they need a way to iterate on further developments for that code base – developments that may run contrary to the goals of the core development team and its customers. Let’s revisit the 3-stage process:
In this diagram, each stage is important for different reasons. The components on the left represent raw open source supply chain components that form the basis for the middle stage. The middle stage serves multiple entities in the ecosystem that springs up around the code base and is a “safe space” where lots of new things are tried, without introducing risk into the various downstream products. You can see echoes of t his in many popular open source-based products and services. Consider the Pivotal Cloud Foundry process, as explained by James Watters in this podcast with Andreessen Horowitz: raw open source components -> CloudFoundry.org -> Pivotal Cloud Foundry, with multiple derivatives from CloudFoundry.org, including IBM’s.
As I’ve mentioned elsewhere, this also describes the RHEL process: raw components -> Fedora -> RHEL. And it’s the basis on which Docker is spinning up the Moby community. Once you’ve defined that middle space, there are many other fun things you can do, including building an identity for that middle distribution, which is what many open source communities have formed around. This process works just as well from an InnerSource perspective. Except in that case, the downstream products’ customers are internal, and there are multiple groups within your organization deriving products and services from the core code base in the middle stage. Opening up the middle stage to inspection and modification increases the surface area for innovation and gives breathing room for the more crazy ideas to take shape, possibly leading to their becoming slightly less crazy and useful for the other downstream participants.
Addendum: none of the above necessitates a specific development methodology. It could be agile, waterfall, pair programming or any other methodology du jour – it’s immaterial. What matters is constructing a process that allows for multiple points of innovation and iterative construction, even – or especially – where it doesn’t serve the aims of a specific downstream product. You want a fresh perspective, and to get that, you have to allow those with different goals to participate in the process.
We have secured space at the Microsoft NERD center in Cambridge, MA, for a meetup on May 23.
We’ll talk about product management in cloud native environments, which basically means the intersection of open source, devops, and continuous integration as it pertains to automated service/product delivery.
So bring your devops hat and get ready to think about risk vectors and how to manage them in this kind of environment. Should be fun!
Product Management in Open Source can be an overlooked topic. Asking questions to define what open source really is, its overall value to a product and what options there are when attempting to scale a project can enable a product to grow with minimal pains. This presentation is an overview on the topic and its details.